Hi all,
In an app I’m working on, I’ve noticed that if I parse a large JSON blob, e.g. 19MB that parsing into PureScript is slow. The data is basically a table of data of about 10k rows.
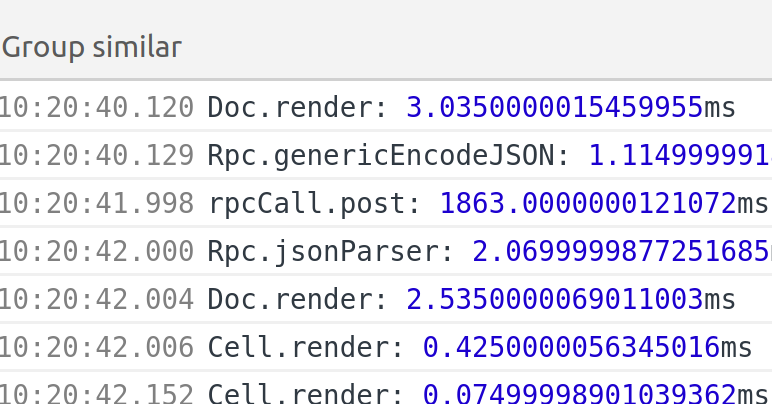
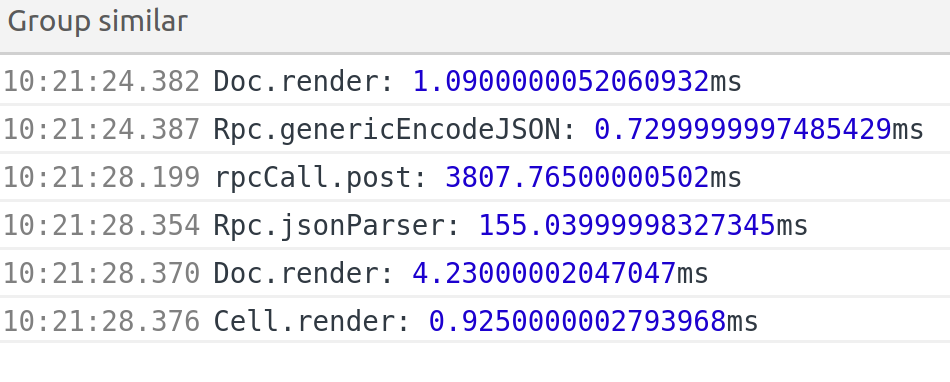
It takes 100ms for the browser to parse this JSON blob into a JS object, which is fine. A JavaScript app would be ready to work with this data promptly.
It takes about 5s for foreign-generic to consume that into a PureScript value. Too slow.
Now, I intend to make my data schema leaner to substantially reduce the redundancy in the JSON output. I also will be paginating data from the server, so I won’t necessarily be sending more than N thousand rows at a time. However, the baseline performance is very important too.
However, there are additional considerations, such as:
-
I will only be presenting about 10-30 rows at a time. With Halogen, I can lazily scroll through the table on-demand, only showing 10-30 rows at once and only rendering that much. (That’s how Google Sheets works. It generates a view of only the rows currently scrolled in view.) But that assumes I’ve already loaded the data.
-
Unlike Haskell, I can’t lazily load the data on-demand like with aeson, which would lex the document (JSON.parse equivalent) and then only allocate objects when I ask for it.
I’ve considered an API like:
foreign import data OutputDocument :: Type
foreign import outputDocumentCells :: OutputDocument -> Array OutputCell
foreign import data OutputCell :: Type
foreign import outputCellUuid :: OutputCell -> UUID
foreign import outputCellResult :: OutputCell -> Result
foreign import data Result :: Type
foreign import caseResult :: forall r. Result -> { resultError :: CellError -> r, resultOk :: Cell -> r } -> r
...
which would simply access the objects as necessary rather than constructing PureScript objects for them.
Sort of like Argonaut, but well-typed. You are able to walk the spine without filling in the contents.
I’ve taken this approach in Haskell with ViewPatterns on a binary format.
Is there any work in the PureScript ecosystem to generate something like this? Essentially, we want to retain the original format sent over the wire and walk it in a type-safe way.
Another way might be like:
-- normal types
data Doc = Doc (Array Cell)
data Cell = ...
-- generated
foreign import data View a :: Type
foreign import docView :: Json -> View Doc -- assumes well-structured JSON
foreign import docCells :: View Doc -> Array (View Cell)
foreign import docMaterialise :: View Doc -> Doc
foreign import cellMaterialise :: View Cell -> Cell
foreign import cellUUID :: View Cell -> String
That would let you choose between a shallow spine-only walk, and when convenient, materialise a view into a proper PureScript object.
A codegen tool (template-haskell, in my case) could consume the normal types and produce the “view” code.
I considered a binary format like flatpack/protobuf/cbor/etc. but I think JSON.parse is plenty efficient, it’s rather the materialization into PS objects that is slow as far as I can tell.
Aside:
I’ve been avoiding writing my own “bridge” between Haskell and PureScript, but
- foreign-generic had a bug where a sum type with nullary constructors was incompatible between aeson and it, which disappointed me. See also my underwhelming exploration of other serialization libraries.
- At this point I think I need full control over performance characteristics.
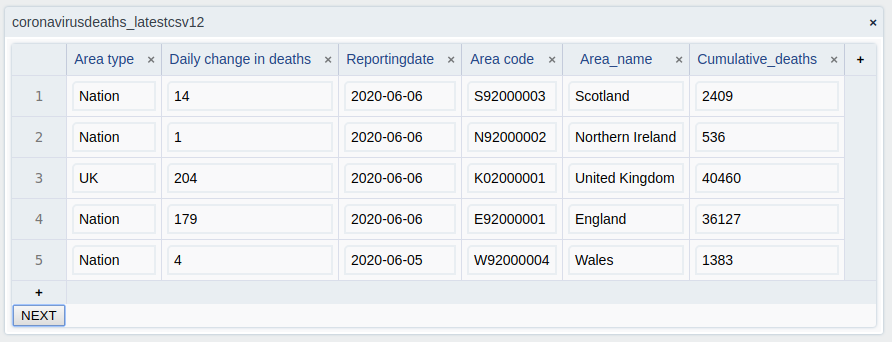
 although not quite as smoothly as in google sheets, as we can also be held up on processing data before it’s ready to display.
although not quite as smoothly as in google sheets, as we can also be held up on processing data before it’s ready to display.