I’m glad to see some work done here, I think the error messages related to rows are ripe for improvement. If we are to simply discuss opinions about error messages I have a few, I’ll let you lot decide their validity and relevance. If anyone cares for more opinions on error messages send me an email or write to me on Discord - I unfortunately don’t hang around GitHub issues as much as of late.
But first some personal option. When I read an error message I usually want it to go away - this means I try to read as little of it as possible. If I see references to the inner workings of the compiler I usually try to gloss over it which is what happened at first when row-types started floating about. This means I value type errors that are legible and have little unnecessary information - which is unfortunately not always the case for row-type errors. These guidelines are of course very vague, and I suspect people will disagree on these points. But to examples are usually illumination. (1) I’ve never found the t64 is an unknown type variable helpful at all; the same goes for the desugared expression - this noise to me. (2) If I can fit more errors in one terminal window I can usually fix them faster - but unfortunately type errors have a tendency to cascade in PureScript; errors hide other errors further down the line which will probably force me to recompile to find them. (3) I want the information in the error messages to be relevant - if you point to a file or line - it should be the place where I can fix my error or figure out how to fix it.
(Already this points to two another solution to the problem of bad error messages: a faster compiler or better error cascading. Both of these solutions will aid other parts as well, not just row-types.)
I’ve been writing PureScript daily now for well over a year, since I am one of few people who work with this language, and I’ve seen a lot of very specific error messages. This is a few of the ones I’ve found that might be of interest. Unfortunately I’m not allowed to share explicit snippets since the code is in a proprietary codebase. These errors I’ve managed to dig up are the ones that are remembered, and that I could draw from the top of my head this Tuesday night - they are not representative of the frequency I find these errors. We also use a coding style where we use a lot of rows in our row-types (around 500 rows all with fairly large types inside them). we were thus forced to fork the compiler and it has saved us days of scrolling through the terminal (I am not kidding with days). This is also the reason for the PR being left alone for the better part of a year - I solved my urgent trouble by working on a fork of the PureScript compiler.
-
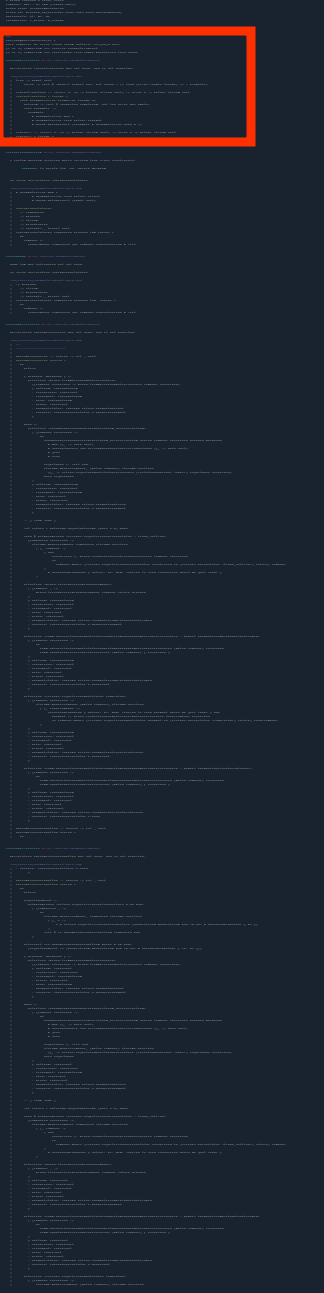
Row unification showing rows that matches, this has resulted in multiple errors which are around 152Kb, this clogs up the terminal and makes it almost impossible to find the error messages. Here is a zoomed out screen shot of one of these errors. The worst part about them is that the type is often written twice for both sides, which is noisy and unnecessary. The screen shot is only of parts of the error message and the red box is the part of it that was actually actionable.
-
If there are errors inside a rowtype with the same name (i.e List imported from say Erlang.List and Data.List), the unification fails and complains about the rows with an error claiming the types are identical. This might be a case of the desuggering, but the row type is relevant here and is strictly not needed.
-
When I get a type error it was inside a record, it used to not report what row was relevant, I think (Mention which row label the type error occurs on by FredTheDino · Pull Request #4411 · purescript/purescript · GitHub) solved that for most cases - but maybe it should be considered here.
-
It wasn’t I who got this message but a colleague got this (and I sadly don’t have the code to reproduce it) - also modified to anonymize.
[1/1 TypesDoNotUnify] Code.purs:204:15
204 ( input # Api.parse
^^^^^^^^^^^^^^^^^
Could not match type
E
with type
Q
while trying to match type
( llllllll :: String
, kkkkkkkk :: Array String
, jjjjjjjj :: Int
, hhhhhhhh :: String
, id :: E
, gggggggg :: Q
, ffffffff :: Int
...
)
with type
( ppppppppp :: String
, qqqqqqqqq :: Array String
, id :: Q
, wwwwwwwww :: String
, eeeeeeeee :: String
, rrrrrrrrr :: String
...
)
I am guessing there were some fields that matched but the records have little in-common when you look at this error.
Of course these are not all the error messages all the time, but they are definitely a source of frustration.
Those are the ones relevant to row errors that I can think of from the top of my head. If one wants to hunt other exotic errors that are quite uninitiative here is a lightning round:
a. If you use a type in a class-declaration without exporting it - the place where the class is instanced throws an error about the class not being imported. This might point to a different file completely, and the type that is not exported is not mentioned.
b. do-blocks as mentioned earlier is a problem if you mix different monads or if you write the wrong return type, since it usually points to a line in the middle which is confusing.
c. The exhaustiveness checker gives up quite eagerly - which forces you to rewrite code in strange ways to please it. For example if you want to case on a large data-enum with a lot of members you are out of luck and have to restructure your case-expressions.
d. Circular dependencies are a nightmare to fix, I audibly groan every single time I get that error. Most of the modules are not relevant to the actual dependency cycle and you end up going on a wild goes chase unless you really know where you’re going with the current change.
But these are just like, opinons, man. <3